

木構造や迷路の探索を行う際、幅優先探索と深さ優先探索を使うことがある。
以下のようなシンプルな木構造を与えられた時、各ノードを探索していくというようなシンプルな実装を考える。
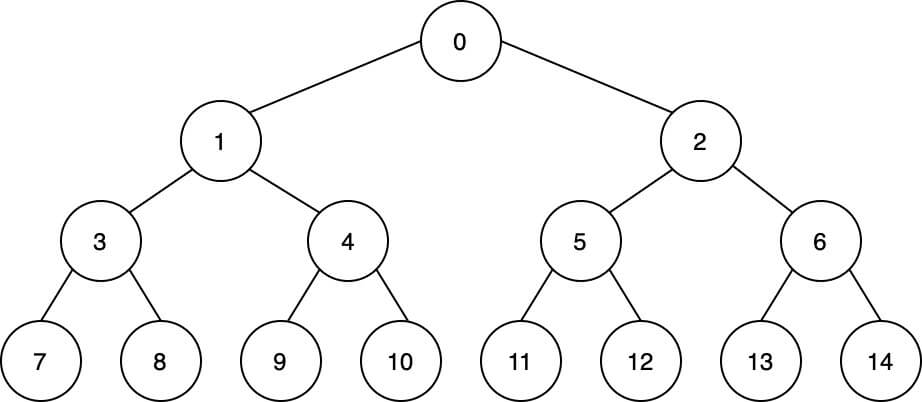
図はこちらのサイトで作成。

Flowchart Maker & Online Diagram Software
draw.io is free online diagram software for making flowcharts, process diagrams, org charts, UML, ER and network diagram...
www.draw.io
幅優先探索はキュー
from collections import deque
tree = [[1, 2], [3, 4], [5, 6], [7, 8], [9, 10], [11, 12], [13, 14], [], [], [], [], [], [], [], []]
queue = deque([0])
while queue:
now = queue.popleft()
print(now)
for i in tree[now]:
queue.append(i)
# 実行結果
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 dequeはデックと読むらしい。
リストでキューを作成するよりも、最初と最後の要素だけO(1)でアクセスできるdequeの方が早い。
Deque とは、スタックとキューを一般化したものです (この名前は「デック」と発音され、これは「double-ended queue」の省略形です)。Deque はどちらの側からも append と pop が可能で、スレッドセーフでメモリ効率がよく、どちらの方向からもおよそ
O(1)のパフォーマンスで実行できます。https://docs.python.org/ja/3/library/collections.html#collections.deque
listオブジェクトでも同様の操作を実現できますが、これは高速な固定長の操作に特化されており、内部のデータ表現形式のサイズと位置を両方変えるようなpop(0)やinsert(0, v)などの操作ではメモリ移動のためにO(n)のコストを必要とします。
深さ優先探索は再帰
tree = [[1, 2], [3, 4], [5, 6], [7, 8], [9, 10], [11, 12], [13, 14], [], [], [], [], [], [], [], []]
def dfs(now):
print(now, end=' ')
for i in tree[now]:
dfs(i)
dfs(0)
# 実行結果
0 1 3 7 8 4 9 10 2 5 11 12 6 13 14 行きがけ順でDFSを実装。
BFSとDFSの使い分け
BFSは探索途中のノードをキューに保存しておく必要があり、メモリ使用量が増える。
DFSは現在のノード情報しか持っていないため、メモリ使用量が少ない。
一方、最短経路を1つだけ見つける場合は、見つかった時点で処理を終了できるBFSの方が実行時間が早い。
DFSは全ての経路を探索した後に、それが最短なのか判定する必要がある。
メモリ使用量と実行時間のどちらを優先するか考えてBFSかDFSを選択する。
以下のLeetCodeの問題がBFSとDFSの取っ掛かりに良いと思う。

Just a moment...
leetcode.com
回答例はこちら。

参考

collections --- コンテナデータ型
ソースコード: Lib/collections/__init__.py このモジュールは、汎用の Python 組み込みコンテナ dict, list, set, および tuple に代わる、特殊なコンテナデータ型を実装しています。,, ...
docs.python.org

コメント