

機械学習を行う際、交差検証(Cross Validation, CV)に基づいてモデルの良し悪しを判断することが多い。
クラス分類であればStratifiedKFoldがそのまま使えるが、回帰の場合は工夫が必要になる。
以下の本を参考に、ビニング(binning)することで連続値を離散値に変換し、クラス分類であるかのようにfoldを振り分けてみた。
この本の元になった英語版の原著はオンラインで無料で読める。この記事に関係するのは26ページあたり。
https://github.com/abhishekkrthakur/approachingalmost/blob/master/AAAMLP.pdf
まずは練習用データを10000個生成。
import pandas as pd
import numpy as np
from sklearn import datasets
n_samples = 10000
_, y = datasets.make_regression(n_samples=10000, n_features=10, n_targets=1)
df = pd.DataFrame({"target":y})
df.hist()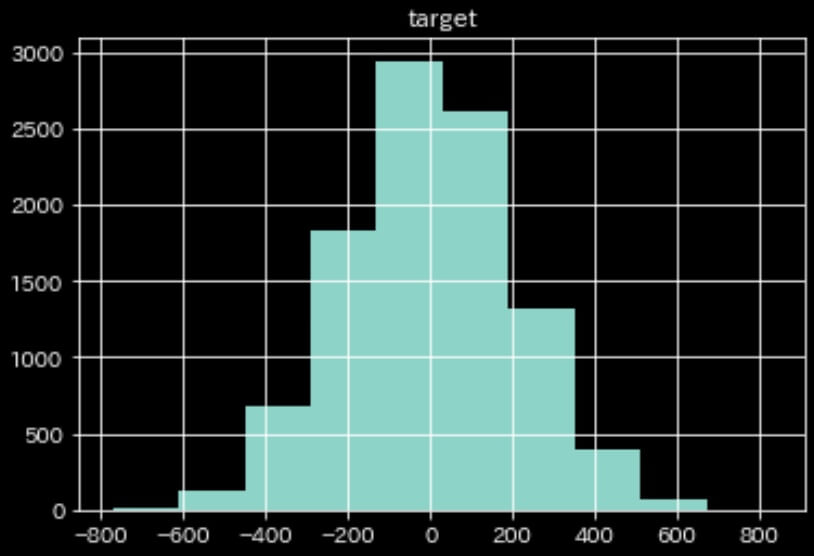
次にビニングを行う。wikipediaによるとビニングの方法は複数通りあるようだが、本にならってスタージェスの公式を適応すると14個にビニングされた。
ヒストグラム - Wikipedia
ja.wikipedia.org
num_bins = int(np.floor(1+np.log2(len(df))))
num_bins # 14pandas.cutでビニングする。

pandas.cut — pandas 3.0.5 documentation
pandas.pydata.org
df["bins"] = pd.cut(df["target"], bins=num_bins, labels=False)
df["bins"].hist()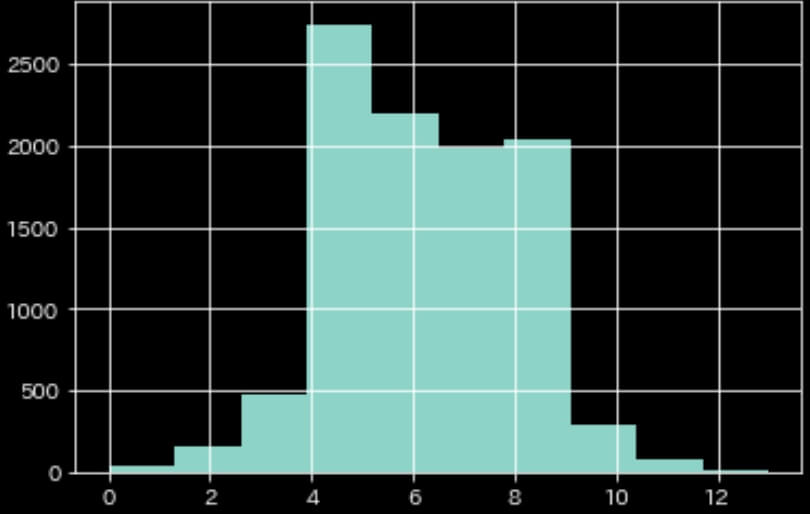
ちょっとヒストグラムの形が変わった。
あとはビニングした値に対してStratifiedKFoldすればOK。
from sklearn.model_selection import StratifiedKFold
df["fold"] = -1
kf = StratifiedKFold(n_splits=3, random_state=42, shuffle=True)
for i, (_, idx) in enumerate(kf.split(df, df["bins"])):
df.loc[idx, "fold"] = i生データに比べるとヒストグラムの形は変わってしまったが、何も考慮せずにKFoldするよりは良いCVが出来そう。

コメント