

KaggleのIndoorコンペにチームで参加し、1170チーム中の15位で上位2%の銀メダルをゲット出来ました。
振り返りも兼ねて解法をまとめようと思います。

チームメイト
ペンギンさん、コロンビアさん、つぼさんと4人で参加しました。
誘って頂き本当に嬉しかったです。



弊チームは4人ともAtCoderなどの競技プログラミングに取り組んでいました。
また、Indoorはモデリングよりもアルゴリズムに基づいた後処理が重要なコンペでした。
競プロはいいぞ〜という思いを込め、Algorithm is All You Need というチーム名にしました。
概略図
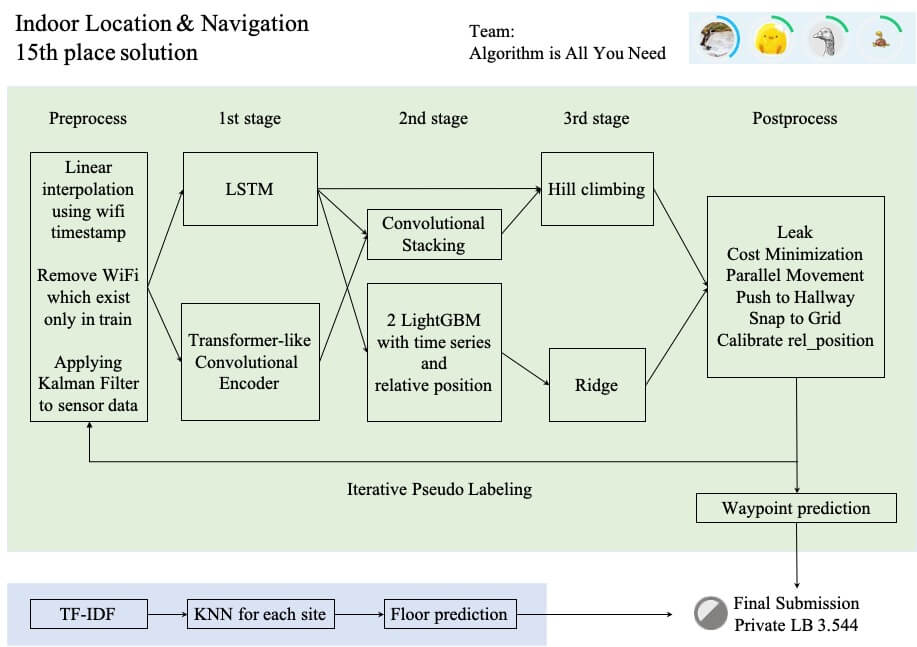
前処理
改行バグの修正
生データには改行バグがあり、これを訂正しないと情報の取得漏れや行のズレが発生してしまいました。
higeponさんのNotebookを参考に、テキストファイルの改行エラーを修正しました。

カルマンフィルタ
コンペのホストからcompute_fという関数がgithubで提供されており、センサーデータから様々な計算を行うことが出来ました。
大活躍する関数なのですが、生のセンサーデータを使うと後述する誤差が大きくなる問題がありました。
カルマンフィルタを適用することでセンサーデータが綺麗になり、compute_fを用いた後処理のスコアを大きく伸ばすことが出来ました。
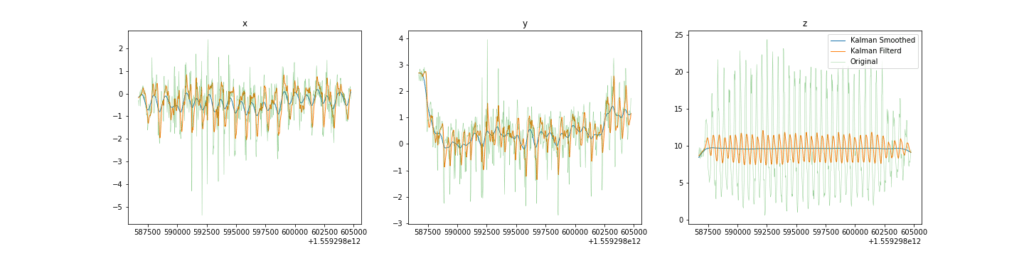
カルマンフィルタは思っていたよりも要求計算量が大きく、GCPでインスタンスを建てて処理しました。
WiFiデータセット
Koukiさんのnotebookを参考にしました。
TrainにはあるけどTestには無いWiFiは除去し、Trainには無いけどTestにしかないWiFiはPseudo Labelingのために残しました。
RSSIは+100した後、0以下の値は全て0にしました。
+100は線形変換で分布を変えないので、結果は変わらないと判断しました。
非負整数の方がぱっと見た時に電波強度が直感的に理解しやすいですし、Embeddingにも使えるので良かったです。
RSSIが0ということはWiFiが届かないという情報を持つので、RSSIが0のBSSIDはno_signalとリネームしてTrainに使いました。
RSSIの値が大きい順にBSSIDとRSSIをソートし、電波が強い順番を保ったままでモデルに入力出来るようにしました。
また、モデルに入力出来るようにBSSIDとsiteはラベルエンコーディングしました。
目的変数であるwaypointのxy座標はTYPE_WAYPOINTに記載されていますが、学習に使う説明変数はTYPE_WIFIにしかありません。両者のtimestampは揃っていないため、何らかの方法で補間が必要になります。
kuto0633さんのnotebookを参考に、timestampを基準にwaypointを線形補間したものを目的変数として採用し、trainとvalidationの両方に使いました。
補間した値をvalidationに使うことに不安がありましたが、CVとLBが相関していたので採用しました。

Koukiさんのデータセットでは、sample_submissionのtimestampに最も近いWiFiの情報が約10000行記載されていました。
しかし、testのWiFiを全て調べてみると、約37000のデータがありました。
そこで、全てのtestのWiFiに対する予測値も計算することにしました。
37000の予測値からsample_submissionのtimestampに合わせて補間することで、提出する形式に揃えました。
そして、sample_submissionのtimestamp直近のWiFiから値を予測するKouki さん形式と、全てのWiFiでwaypointを予測してから後で補間する弊チーム形式の2種類をアンサンブルすることにしました。
Cross Validation
同じPathにある情報がValidationに入ってしまうとリークを起こしてしまうので、PathをGroup、siteをラベルとしてGroupKFoldしました。
pathが別々でも同じ通路を歩いているとBSSIDやRSSIが被ってしまうので、厳密にはpathに現れるBSSIDの個数やRSSIの値も考慮してCVする必要があったと思われますが、実装出来なかったのでrandom seed averagingとfoldの切り方を少し工夫して対処しました。
CVは5 fold に設定していましたが、n_splitsは15にしました。
n_splits=5だと、どれをvalidationにするかの選び方は5C1=5通りしかありませが、n_splits=15だとvalidationに現れるpathの組み合わせは15C3=455通りになります。
seedを変えて様々なpathの組み合わせを学習してaverage/ stackingすることで、5 CVの学習であったとしても前述のBSSID / RSSIが被ってしまう問題を緩和し、CVとLBが高い相関を示すようになりました。
Floorモデル
フロアモデルは2種類作っていました。
1つ目はFinal Submissionで採用した各site毎のKNNモデルです。
Indoorコンペの各siteにおいて、複数フロアにまたがって同じWiFiが観測されていました。
実際の建物をGoogleストリートビューやホームページで確認してみると大きな吹き抜けが多数あり、上下階のWiFIが届くのも納得でした。
しかし、WiFiが届くと言っても同一フロアの方が電波が強いでしょうし、他の階の電波は弱いはずです。
そこで、BSSIDを単語、RSSIを単語の出現回数というように解釈しました。
仮説としては、電波が強い→RSSIが大きい→BSSIDの出現回数が多い→同一フロアのが可能性高い、という形になります。
TF-IDFでベクトル化した値をKNNに入力することで、各フロアのクラスタに分類されるのでは?と考えていました。
実際、このKNNは100%正解しておりました。
2つ目のフロアモデルは、上記KNNとsimple99、NNの3つを多数決したものです。
NNはsite x floor の多クラス分類として解きました。
偏りがあるクラス分類でしたが、Focal Lossを使うことでCVがほぼ100%近くになりました。
simple99はRで公開されていたnotebookをPythonに移植し、結果を再現するとともにパイプラインに組み込みやすくしました。

フロアモデルはmamasさんの方法で精度を確認し、Publicを100%正解していることを確認しました。

Final subではWaypointを固定し、Floorモデルを2種類に変えて提出しました。
KNNはCVで精度が良かっですし、多数決モデルと結果を比較するとほぼ一致していました。
2種類のモデル間で答えが合わなかった所がスコアへの影響が大きいと考えてのフロア2種類subとなりました。
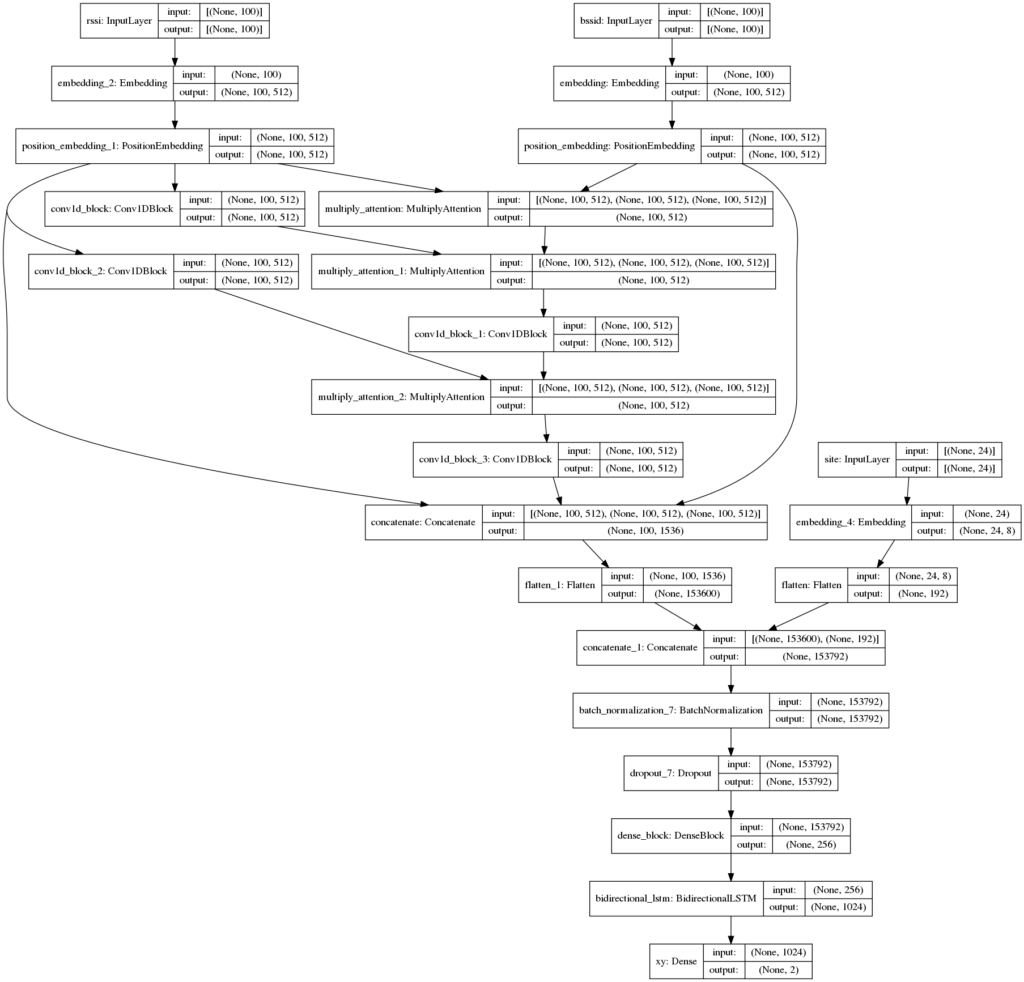
Waypointモデル
1st stage
モデルは2種類使いました。時系列モデルを組もうと思いましたが、知識が無く実装できませんでした。
1つ目はKoukiさんの公開ベースラインをOptunaでパラメータチューニングしたものです。

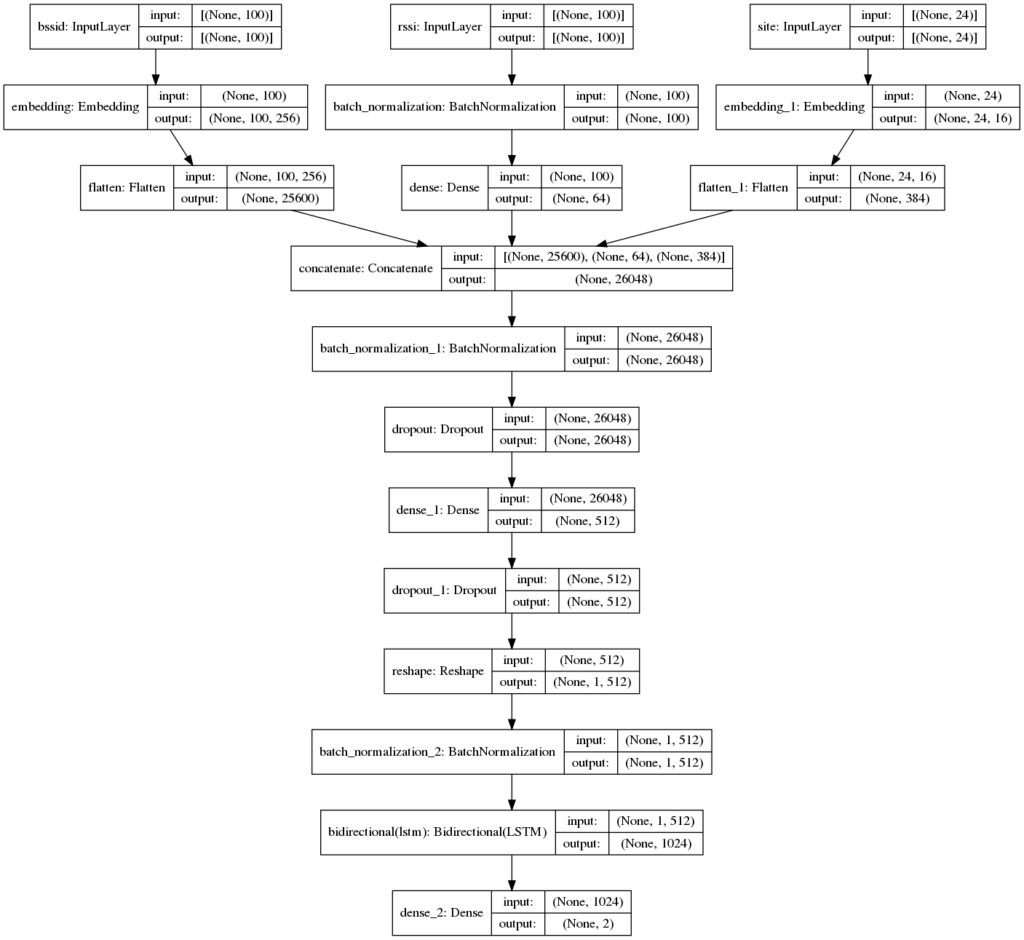
2つ目はTransformerのEncoderにConvolutionを組み合わせて改変したモデルを使いました。
出力部分はKoukiさんのLSTMを踏襲しています。
最初はオリジナルのTransofmerのEncoderを実装していたのですが、学習が上手く進みませんでした。
BSSID / RSSIは強度順にソートしてあったので、隣接するWiFiの関係性が位置を予測するのに重要だろうというアイデアを思き、Covolutionなら隣接する情報を畳み込んでいってくれるのでは?と考えました。
Convolutionを入れるとチャンネルの情報が重要になるのですが、Feed Forward Networkはチャンネル方向に働いてしまって悪影響を及ぼす可能性があったので除外しました。
また、Multi Head Attentionは乗算の方がよりWiFiの位置関係を強調するだろうと考え、Addの代わりにMultiplyを採用しました。
BSSIDをQuery、RSSIをKey,Valueにし、BSSIDから情報を引き出していくような形にしました。
以上の工夫を加えることで、1つ目のモデルよりもCVが0.1〜0.2ほど伸びました。
class Conv1DBlock(tf.keras.layers.Layer):
def __init__(self, filters, kernel_size, dropout_rate):
super(Conv1DBlock, self).__init__()
self.conv = tf.keras.layers.Conv1D(filters, kernel_size=kernel_size, strides=1,
padding="same", activation=None)
self.norm = tf.keras.layers.BatchNormalization()
self.act = tfa.activations.mish
self.dropout = tf.keras.layers.Dropout(dropout_rate)
def call(self, x, training):
x = self.conv(x)
x = self.norm(x)
x = self.act(x)
x = self.dropout(x, training)
return x
class MultiplyAttention(tf.keras.layers.Layer):
def __init__(self, key_dim, num_heads, dropout_rate):
super(MultiplyAttention, self).__init__()
self.att = tf.keras.layers.MultiHeadAttention(key_dim=key_dim, num_heads=num_heads)
self.dr1 = tf.keras.layers.Dropout(dropout_rate)
self.norm1 = tf.keras.layers.BatchNormalization()
def call(self, qkv, training):
q, k, v = qkv
att = self.att(q, k, v)
att = self.dr1(att, training)
q *= att
q = self.norm1(q)
return qしかし、結果的にはこのモデルは不要だった可能性が高いです。
後処理に力を入れる前にモデリングで何とかしようともがいた結果なので、後処理が強力になってしまえば重い割に精度が出ない非効率なモデルでした。
コンペが終わった今思えば、OptunaでチューニングしたLSTMで既に十分なパフォーマンスを発揮していたと思われます。
上記モデルは2つとも10種類のseedで学習を行い、20個の結果を得ました。
学習にはColab Proがとても良かったです。
GCPでGPU/TPUインスタンスを立てるよりも遥かに安く、3〜4並列実行することで5CVの複数seedも十分実行可能でした。
2nd stage
Convolutional Stacking
1st stageで2モデルx10seed=20モデル分の結果が手に入りました。
単純平均だけでもスコアは伸びるのですが、モデルの違いやseedの違い(=学習したpathの組み合わせの違い)を考慮した方がもっとスコアが伸びるのでは?という思いがありました。
また、全結合によるstackingでは全てが結合された1次元配列になり、モデルやseedの違いが失われてしまいます。
そこで、Convolutionを使ってstackingすることにしました。
入力次元は(バッチサイズ、waypointのxy座標、モデル数、1)=(batch, 2, 20, 1)となります。
Convを適用するために1次元拡張し、モデル方向に畳み込むことで結果の違いを学習させて行きます。
20ピクセル、1チャンネルの画像というように捉えると分かりやすいでしょうか?
また、それぞれの座標にも何らかの関係性も何かあるはずだと思い、stackingの際はx座標、y座標、xy座標を出力するような形にしました。
xy座標を学習させるブロックだけ最初はConv2Dでxy間を学習させ、その後はx座標単体とy座標単体のブロックと同様Conv1Dで畳み込んでいきます。

これで単純平均よりもスコアが伸ばすことが出来ました。
このstackingも10 seed行い、1st stage と合わせて 3rd stageに入力します。
LightGBM stacking
もとのモデルは点で予測を行っており、waypoint同士の繋がりやセンサーデータを情報として取り込めていませんでした。
そこで、予測の前後情報を用いたLightGBMを2つ構築しました。
特徴量として、以下のものを作成しました。
- 前後n個の予測値
- 前後n個の予測値との差分
- 前後n個の予測値からの変化率
- 前後n個の予測値同士の差分
- 移動平均
- 移動分散
- 相対位置(compute_f,rel_position)
- 相対位置の累積和
- 予測値と相対位置の累積和の差分
- path毎の集約特徴量(mean,max,min,median,std,sum)
3rd stage
Hill Climing
1st stage のモデル2つと、2nd stage のConvolutional Stackingに適応しました。
結果を単純平均するだけでも良いのですが、もっとスコアを伸ばすために加重平均したくなりました。
しかし、30個の結果からベストスコアを生み出す重み30個を全探索していてはかなりの時間がかかってしまいます。
そこで、山登り法(Hill Climbing)を使ってCVを最小化するような重みの探索を行いました。
焼きなまし法と違って局所最適解に陥ってしまう可能性がありましたが、実装が楽だったので山登り法を採用しました。
これにより計算量を落としながらも良い重みを見つけることができ、単純平均よりもスコアが伸びました。
後処理なしで Public LB が 4.245 となりました。
Ridge回帰
LightGBM stackingに適応しました。
Hill Climbingと同様、単純平均よりも最適な重みで加重平均したいというモチベーションで採用しました。
2つのLightGBMをRidge strackingすることで、後処理無しの Public LBが 1st Stageの4.452 から4.118 へと大きく改善しました。
後処理
Indoorコンペで重要な部分を占めるパートです。
弊チームでは以下のようなパイプラインを組み、繰り返し後処理を適応しました。
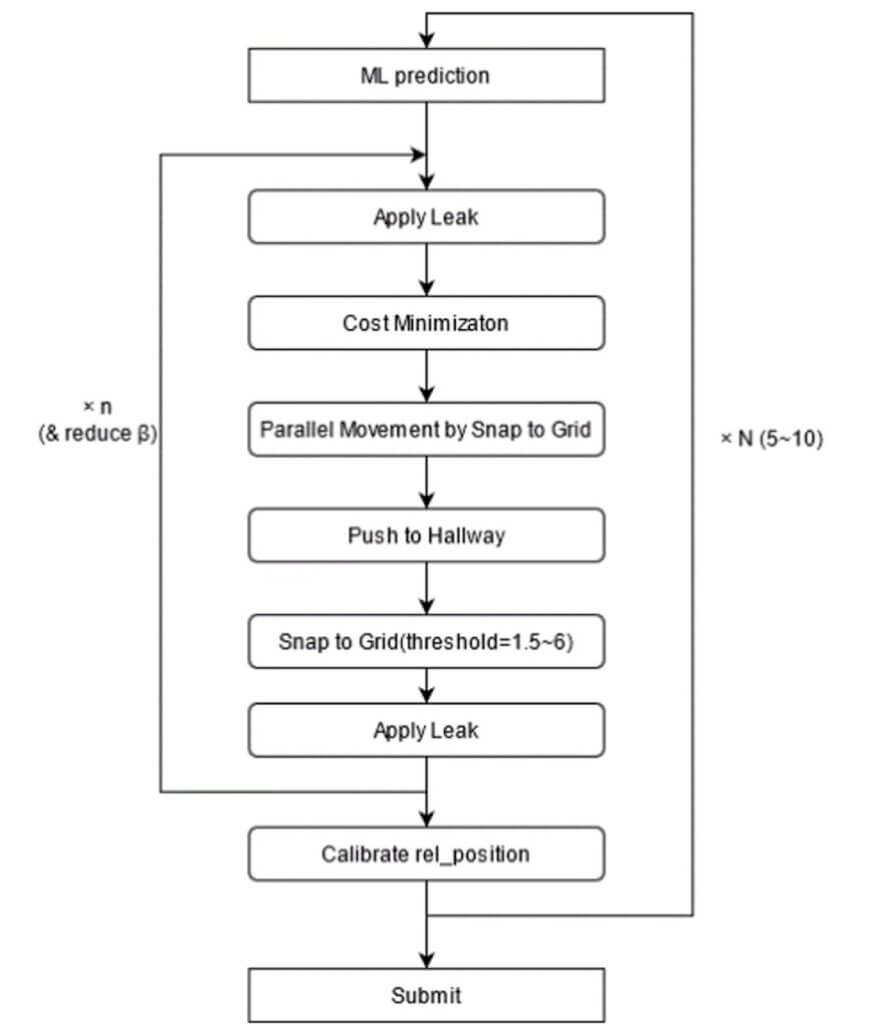
リーク
tomooinubushiさんのnotebookを参考にしました

上手くリークを活用する方法を思いつかず、公開されている通り始点と終点を揃えることのみ行いました。
Snap to Grid
robikscubeさんのnotebookを参考にしました

waypointはTrainとTestで被っている可能性が高かったため、Snap to Gridは効果的でした。
弊チームでは繰り返し後処理を行っていたため、最初の数回は閾値高めに設定してsnapされる確率を上げ、精度が高まってくる後半は閾値を下げて過剰なsnapを避けました。
Parallel Move
Snap to Gridは近くのwaypointに強制的にSnapさせるため、もとのpathの形が大きく崩れてしまう可能性があります。
特に、予測値の多くが壁の中にあった場合に東西南北どこのwaypointにsnapされるのか予想がつかず、Snap後はぐちゃぐちゃな形になり壁の中を往復するような形になってしまう可能性がありました。
そこで、Snap to Gridを適応する前に、Snapされやすそうな方向にpathの形を保ったまま平行移動することを考えます。
もとの座標とSnap to Grid後の座標の差を取り、その平均値dx, dyがSnapされやすい方向だと考えます。
もとの座標にdx, dyを加算することでpathの形を保ったままSnapされやすそうな方向に平行移動することができました。
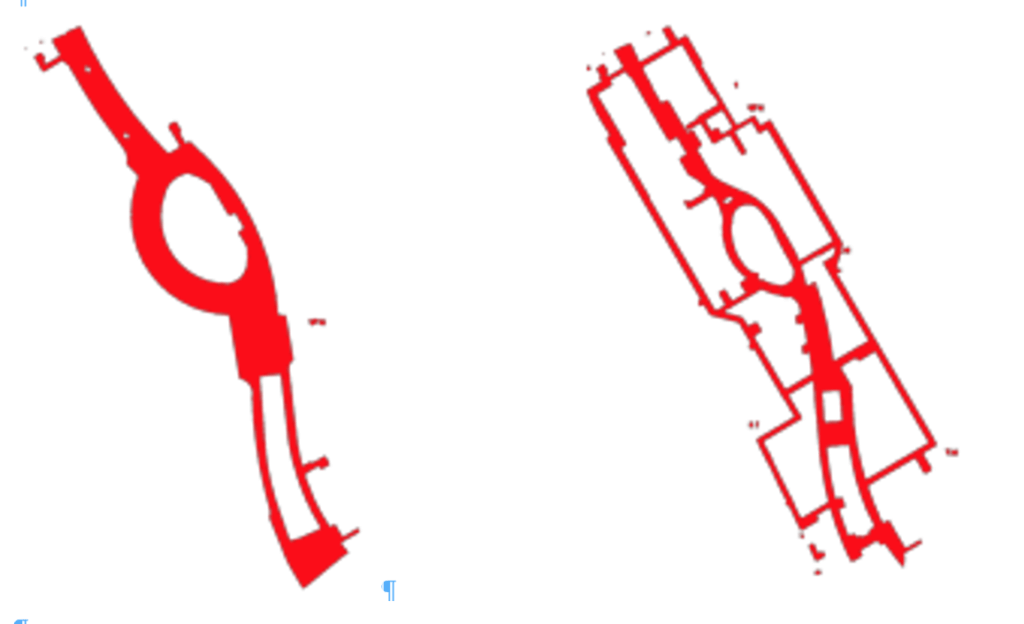
Push to Hallway
予測値が壁の中にあった場合、通路に動かす必要があります。
Snap to Gridでも同様のことが可能ですが、ただ単に閾値を大きくするだけだとwaypointがない通路にはSnapされず、想定外のSnapが起きてしまいます。
そのため、Snap to Gridを行う前に予測値を通路に移す処理が必要となります。
フロアの画像のピクセル値から壁か通路かを判定し、予測値を最寄りの通路の座標まで動かすことで対処しました。
Cost Minimization
saitodevel01さんが公開して下さったnotebookを参考にしました。

非常に強力だったため、弊チームでは有効活用する方法を日々研究していました。
まずは計算式を眺めてみます。
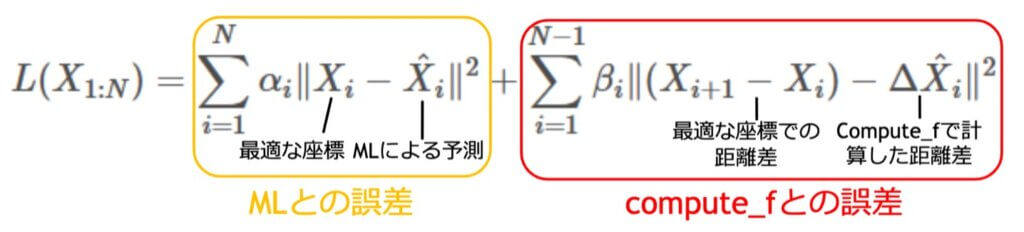
X^は予測値を代入する部分です。
なので、後処理をすることで綺麗になった値を再度代入することで、より良くなった結果が帰ってくる、ということが想像できます。
そのため、Cost Minimizationをループ処理させて繰り返し適応したいという気持ちになります。
⊿X^はホストがgithubで提供しているcompute_fを使います。
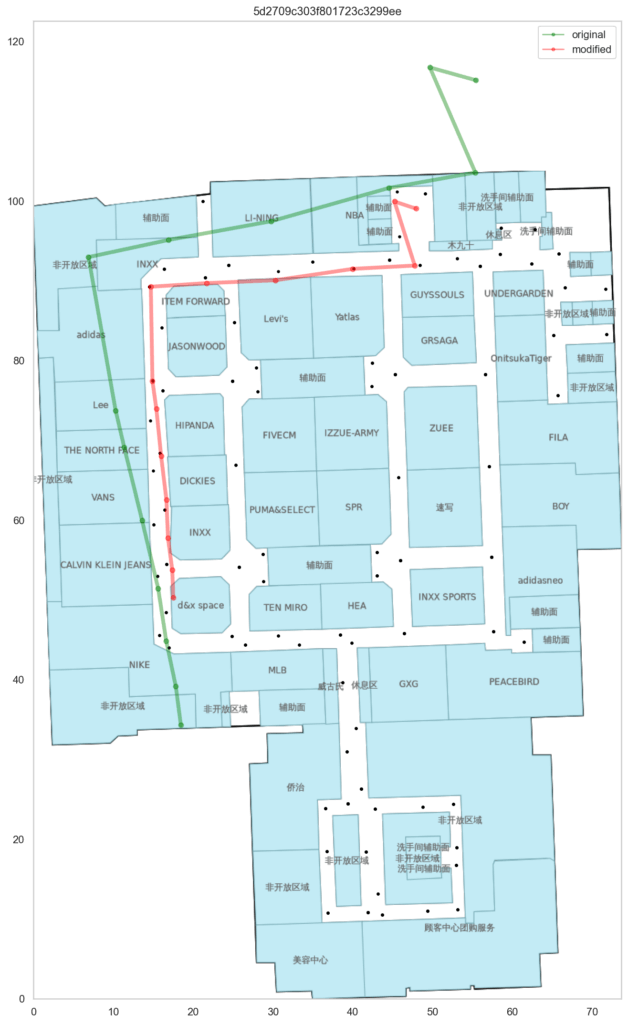
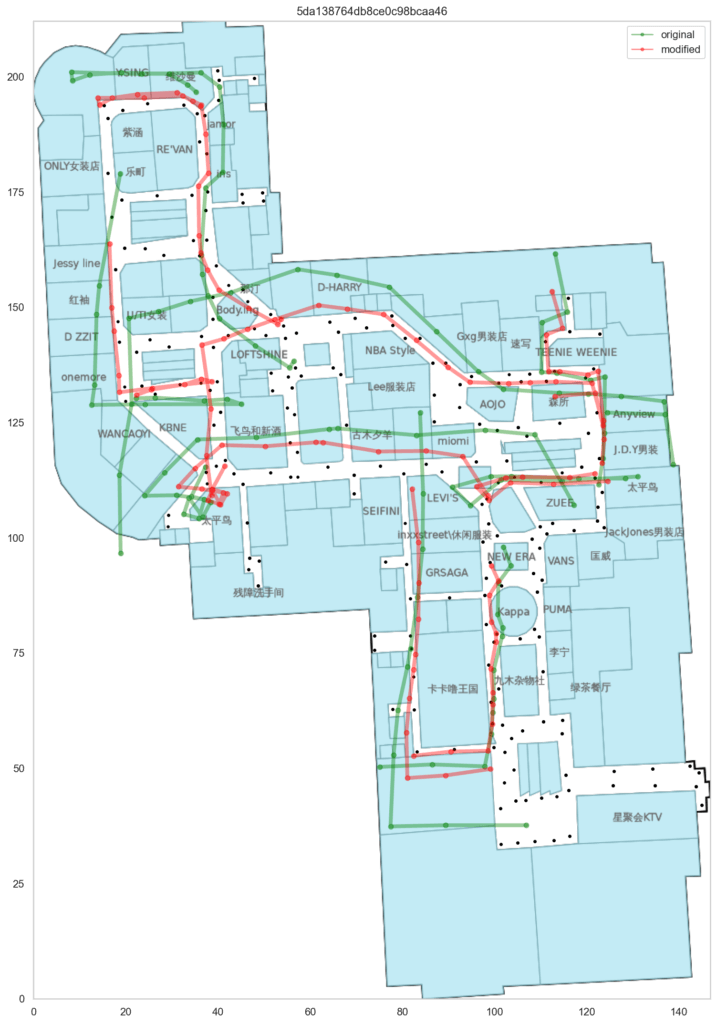
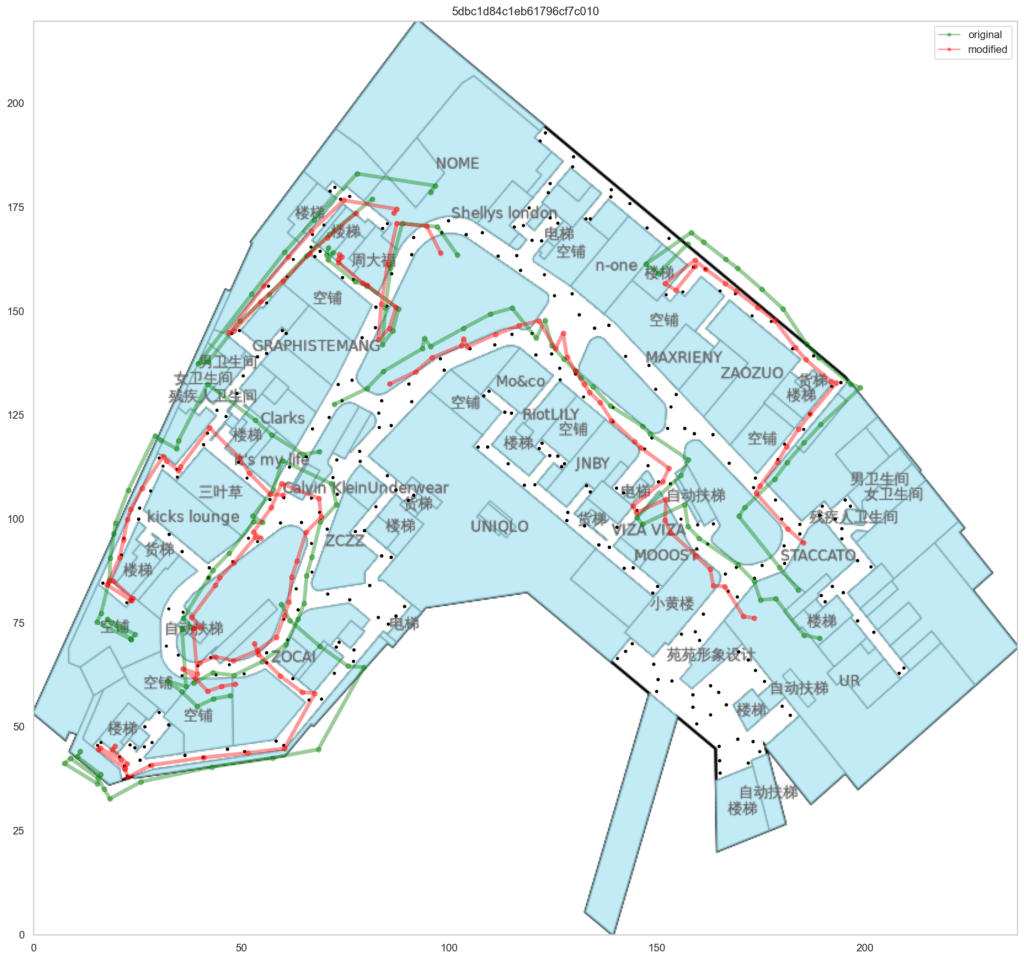
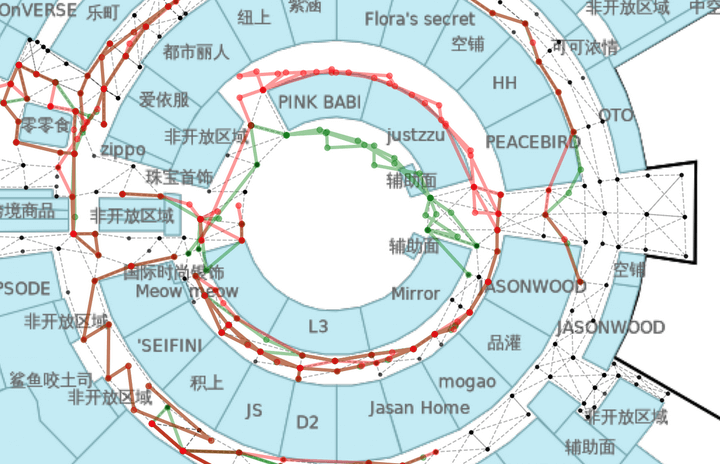
まずはTrainのデータを使って可視化し、compute_fの精度を見てみます。
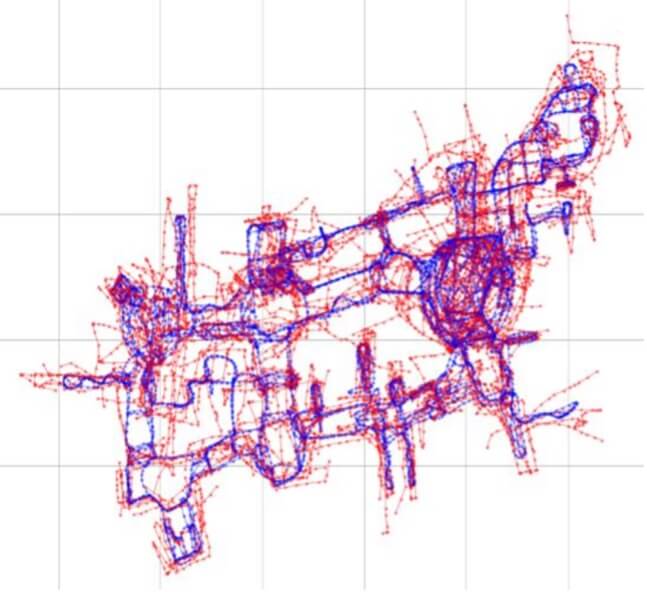
青がTrainのwaypointで、赤がrel_positionによる予測値です。
compute_fによる予測値はオリジナルと比べて約1.2倍拡大され、さらに回転されていることが分かりました。
そのため、compute_fの計算に使われるセンサーデータを綺麗にする必要があります。
これが前処理の段落で述べたカルマンフィルターです。
カルマンフィルタを使ってセンサーデータを綺麗にすることで、compute_fを以下のように修正することができ、スケールが1.2倍されてしまう問題が緩和されました。
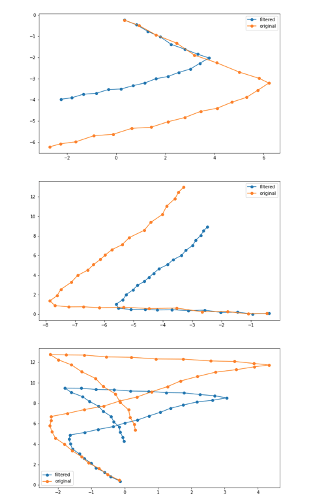
しかし、rel_positionが回転しまう問題が残っています。
赤がrel_positionによる予測値なのですが、青のTrain waypointに比べて角度がずれています。
これを修正する方法を考えます。
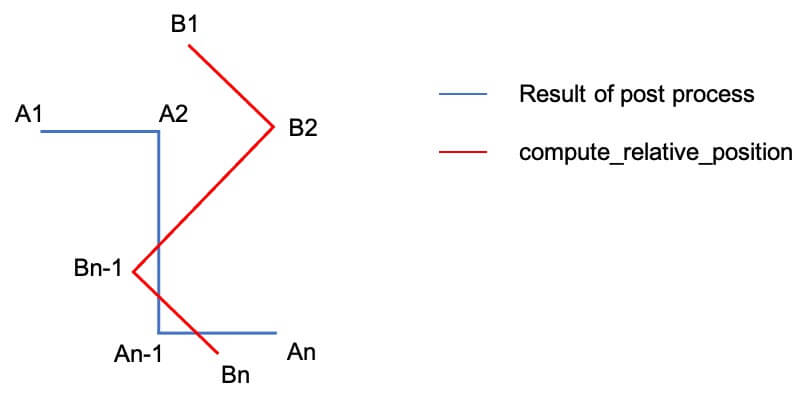
後処理した後のあるpathにおける予測座標を始点から順にA1、A2、…Anとし、compute_rel_positionsによる予測座標をB1、B2…Bnとします。
もし回転が起きていなければ、A1→A2の移動量delta_aと、B1→B2の移動量delta_bは大体同じになるはずです。
しかし、可視化で分かった通りcompute_rel_positionsはθ度の回転が起きてしまいますので、delta_aとdelta_bは一致しません。
そこで、delta_aとdelta_bの差が最小になるように、delta_bの修正角θを探索します。
損失関数をdelta_aとdelta_bの距離の総和、つまり
loss(θ) =||(A2-A1) – (B2-B1)R(θ)||^2 + ||(A3-A2)-(B3-B2)R(θ)||^2 + … + ||(An-An-1) – (Bn-Bn-1)R(θ)||^2
とし、このlossの最小化を試みます。
ここで、R(θ)は座標をθ度回転させる回転行列であり、例えば (B3 – B2)R(θ) はB2→B3をθだけ回転させたものを表します。
また、|| X – Y||^2 は、移動量X, Yの差の二乗を表します。
つまり、損失関数は「現在の移動量」と、「compute_rel_positionsによって計算された移動量をθだけ回転させた移動量」の違いを表しています。
損失関数の値が小さくなるθほど、Bの角度がAに近いことを意味します。
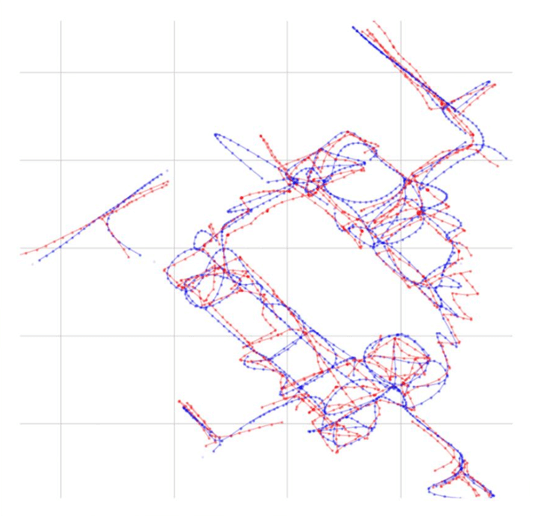
これによりpathごとの最適なθを求めcompute_rel_positionsの回転を補正することが出来ました。
そして、Cost Minimizationを繰り返し適応することによる誤差の拡大を抑えることに成功しました。
ここで、オリジナルと修正後のcompute_fを比較してみます。
精度が良くなっていることが一目瞭然ですね!
compute_fの誤差や回転が改善したところで、もう一度計算式を見てみます。
αとβはモデルの予測値とcompute_fの予測値を重み付けして加算するパラメータになっています。
αが高ければモデルの予測値を優先することになり、βが高ければcompute_fを優先することになります。
後処理を繰り返し適応することでモデルの予測値が良くなっていくと考えられるので、後処理の回数が増えるほどαを増加、βを減衰させるようにしました。
Iterative Pseudo Labeling
Pseudo Labelingを繰り返すことで、どんどんスコアが伸びていきました。
Grid Generationを使っていなかったので、waypointが無い所の恩恵が大きかったのかな、と思います。
Final submission
後処理後の精度を検証する方法を思いつかなかったため、ひたすら目視しました。
コンペ後半ではチーム全員の眼力が磨かれ、pathの良し悪しを語り合っていました。
目視した際に大きく外しているpathがそこまで無かったため、Final subはwaypointを信じてフロアを2種類出すことにしました。
フロアがスコアに与える影響が大きいため、shakeが起きるとしたらフロアかなという予想がありました。
弊チームは最終日のLBでは銀圏上位だったため、手堅く銀圏に残るよりも金圏へのshake upを期待してのフロア2種類選択でした。
Snap to Gridはフロアの影響を受けるため、Final subを2つとも可視化し、チーム全員で目視して妥当だと判断しました。
結果はPrivateでも最も高いスコアのsubを選択しており、眼力が鍛えられていた結果となりました。
またフロアも全問正解しており、不意なshake downを避けることが出来ました。
悩んだpath
Train waypointが無い部分です。
testのpathが内側の緑色の先を歩いていたのか、その1つ外側の通路の赤色の線を歩いていたのか、検討がつきませんでした。
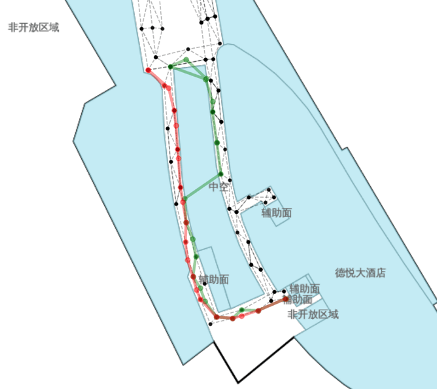
このpathも悩みがありました。
compute_fによる予測では緑色の経路が正しそうに見えましたが、吹き抜けを横切っており空中を歩いていることになります。
となると赤い線が正しい予測なのか?とも思いましたが、実際の建物をネットで検索してみると中空に通路のようなものがあり、橋渡しのようになっていました。
もしかしたらフロアの図面が間違っていて実際は中空の通路を横切っているのかも?という考えが最後まで残り、自信が持てませんでした。


その他のtest pathは「まぁまぁ良い感じじゃない?」という予測に落ち着いており、目視確認のsubmissionにもある程度の安心感はありました。
上手く行かなかったこと
時系列NN
WiFiとセンサーデータを全て統合したデータセットを使ったNN
siteごとのNN
全データを事前学習した重みの転移学習
ダイクストラ、ワーシャルフロイド、幅優先探索
マップマッチング
Curve to Curve
Gridの生成
感想
Grid Generation無しでも銀圏上位に残れたため「弊チーム結構すごいのでは?」と思ったりしています。
後処理なしでモデルの予測値だけだと銅メダル下位でしたが、強力な後処理によって銀メダル上位まで上がりました。
競プロ力、すごい!
また、コンペ終了後にペンギンさんがLeader Board Probingを行いました。
競プロ的な要素が入っているので、興味があれば是非ご覧下さい。

コメント