

ニューラルネットを構築する際、ハイパーパラメータの選択をする場面が多々ある。
人力やグリッドサーチでは取りこぼしがあるかもしれないので、ベイズ最適化を使ったライブラリ optuna でハイパーパラメータチューニングを行いたい。
並列で最適化を進めることが出来ればチューニングにかかる時間を減らすことができ、コンペや仕事の締め切りなどで時間があまり取れない場合に有効になる。
ざっくりまとめると、結果を格納するDB作成して複数プロセスで実行するだけ。
基本的な使い方は他の記事で分かりやすいものが多いため割愛。
def objective(trial: optuna.Trial):
tf.keras.backend.clear_session()
model = my_keras_model
loss = my_metrics
return loss
study_name = "my_opt"
study = optuna.create_study(pruner=optuna.pruners.PercentilePruner(60),
storage=f"sqlite:///{study_name}.db",
study_name=study_name,
load_if_exists=True)
study.optimize(objective, n_trials=200, gc_after_trial=True)最適化したい関数objectiveを定義し、最小化したい値lossを返すようにする。
create_studyでstorageにDBを指定する必要があるが、存在しなければ勝手に作成してくれるので予め作る必要はない。
load_if_existsはDBが存在する場合に履歴を引き継いで最適化を継続してくれるのでTrueにする。
主観だが枝刈りのprunerにはPercentilePrunerが良いような気がした。
MedianPrunerだと今までの結果の中央値より悪ければ打ち切ってしまうが、LR schedulerやReduceLROnPlateauなどによって後からモデルが改善される場合もあるため、枝刈りされすぎるのもどうかなーと思った。
PercentilePruner(60)で今までの6割以下の成績で打ち切るようにし、少し判定条件を優しくした。
メモリが溢れかえることを防ぐため、objective関数の中にclear_session()、study.optimizeの引数にgc_after_traialを入れる。
pythonファイルが完成したら、ターミナルをたくさん開いて同じファイルを実行しまくる。
1つのDBを同時に参照しながら並列で最適化が進んでいく。
複数GPUある場合は、GPUの数だけターミナルを開き、
CUDA_VISIBLE_DEVICES=0 python my_opt.py
CUDA_VISIBLE_DEVICES=1 python my_opt.py
を実行すればOK。
軽量モデルなら
CUDA_VISIBLE_DEVICES=0 python my_opt.py
CUDA_VISIBLE_DEVICES=0 python my_opt.py
CUDA_VISIBLE_DEVICES=1 python my_opt.py
CUDA_VISIBLE_DEVICES=1 python my_opt.py
のように、1つのGPUで複数走らせてもいい。
クラウドだと時間あたりの課金になるし、ローカルマシンを使うにしても電気代や排熱があるので、GPUを限界まで使い倒してさっさと終わらせよう。
study.optimizeの引数にn_jobsがあるが、Tensorflow/KerasとGPUの時にはうまく働かない。
CPUとsklearn等ならn_jobs=-1がちゃんと動くと思われる。
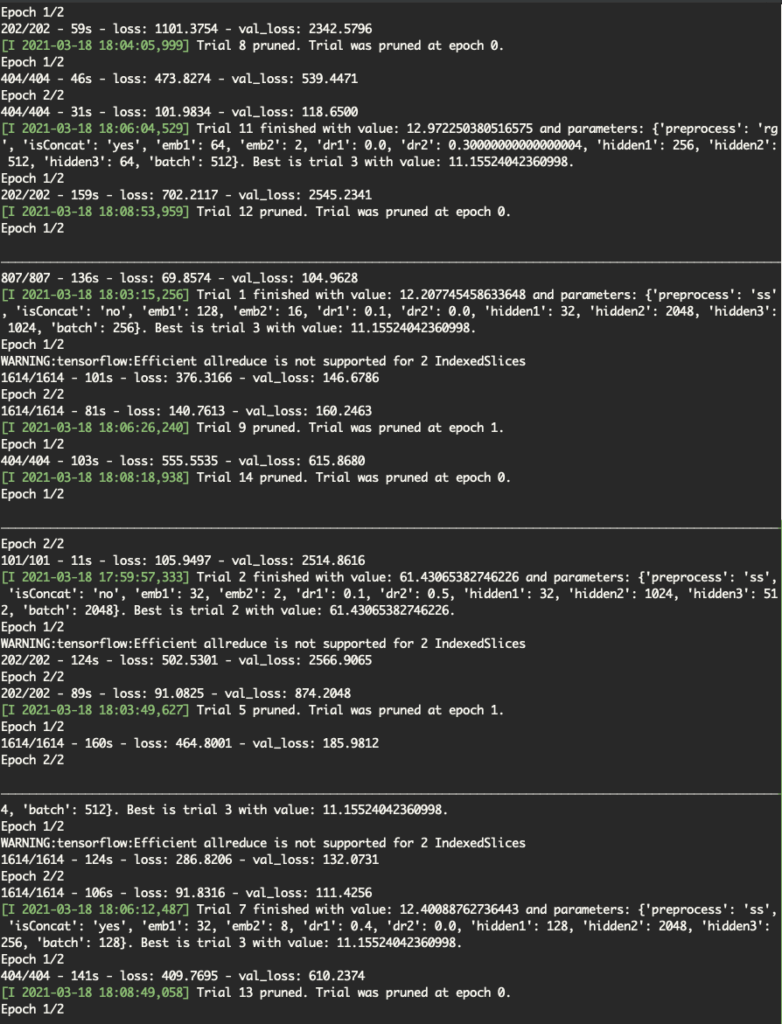
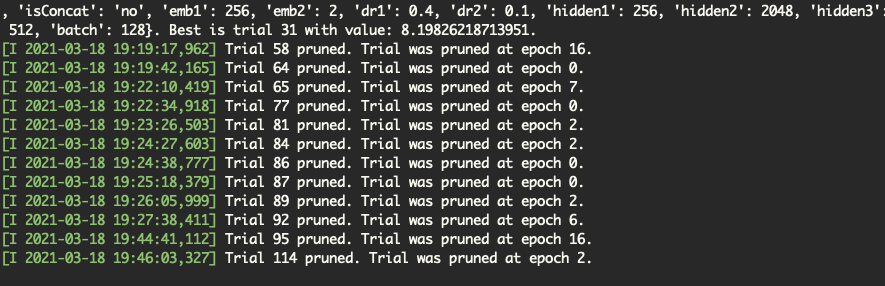
今回は全結合だけの軽量モデルだったのでn_trials=200にしたが、途中で良いパラメータが見つかって後半はほとんど枝刈りされていた。
PercentilePrunerを70~80に緩和するか、n_trials=100ぐらいで打ち切るか、計算資源と時間の兼ね合いで調整した方がいいかもしれない。
参考





コメント