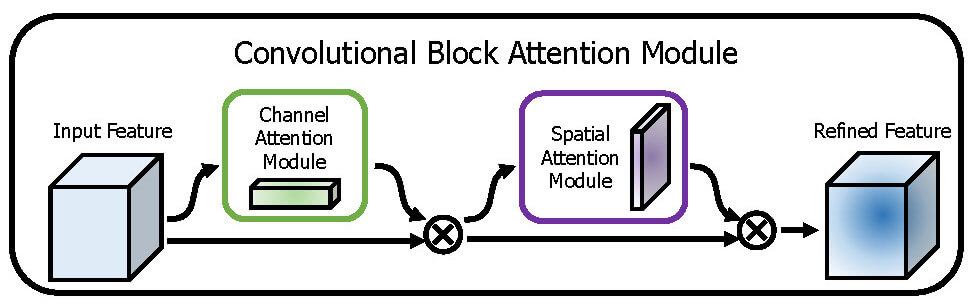
CNNに使えるAttentionとして、Convolutional Block Attention Moduleがある。
チャンネル方向のアテンションと空間方向のアテンションを組み合わせることで重み付き特徴マップを作成し、CNNの認識精度を高める手法である。
CNNの最終層をFlattenやGlobalAveragePoolingだけで済ませてしまうと、チャンネルや空間に含まれる情報が欠落してしまうかもしれないと考えられるので、アテンションを間に挟んだほうがいいのではないかと想像。
Channel Attention
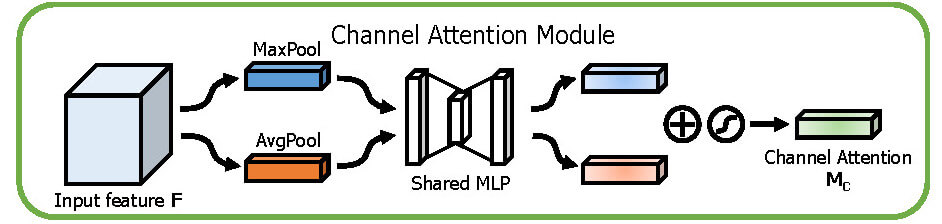
図だけ見るとMaxPoolとAvgPoolをConcatしてMLPに入力しているように見えるが、MLPは共有レイヤーなので勘違いしないよう注意する。
2つ目のMLPは活性化関数を通さないので、コピペして”relu”等が入らないようにする。
小さいMLPを挟んで元の次元数に戻してる所がAutoEncoderに近いものを感じる。
特徴量の圧縮のようなことをしているんだろうか?
def ChannelAttentionModule(input: tf.keras.Model, ratio=8):
channel = input.shape[-1]
shared_dense_one = tf.keras.layers.Dense(channel // ratio,
activation='relu',
kernel_initializer='he_normal',
use_bias=True,
bias_initializer='zeros')
shared_dense_two = tf.keras.layers.Dense(channel,
kernel_initializer='he_normal',
use_bias=True,
bias_initializer='zeros')
avg_pool = tf.keras.layers.GlobalAveragePooling2D()(input)
avg_pool = tf.keras.layers.Reshape((1, 1, channel))(avg_pool)
avg_pool = shared_dense_one(avg_pool)
avg_pool = shared_dense_two(avg_pool)
max_pool = tf.keras.layers.GlobalMaxPooling2D()(input)
max_pool = tf.keras.layers.Reshape((1, 1, channel))(max_pool)
max_pool = shared_dense_one(max_pool)
max_pool = shared_dense_two(max_pool)
x = tf.keras.layers.Add()([avg_pool, max_pool])
x = tf.keras.layers.Activation('sigmoid')(x)
return tf.keras.layers.multiply([input, x])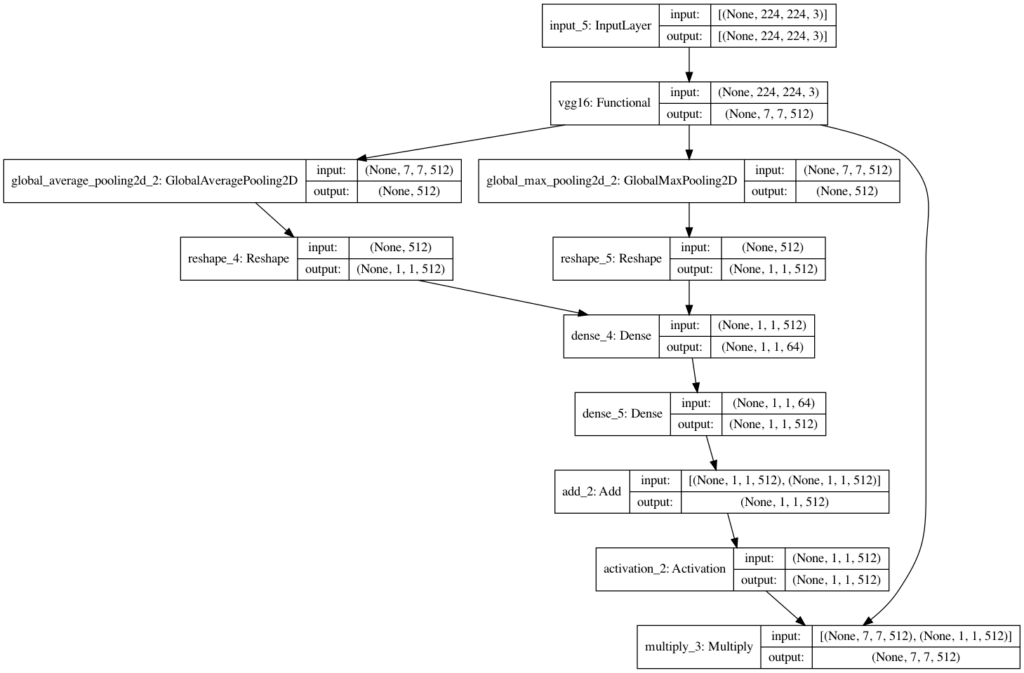
Spatial Attention
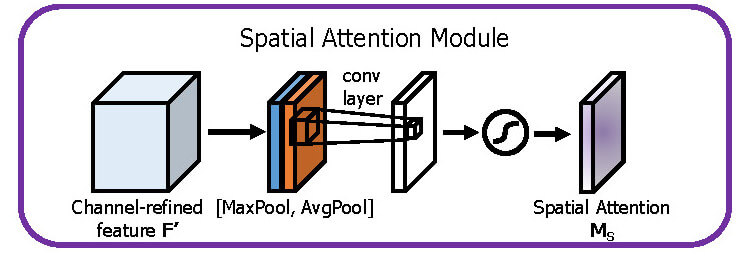
チャンネルと同様MaxPoolとAvgPoolを取るが、GlobalPoolingは空間方向には使えない。
手間だがLambdaレイヤーとtf.keras.backendで自作する必要がある。
また、MLPと違ってConvレイヤーではバイアス項が無い。
元論文ではkernel_size=7でConvを1回だけしているが、最終出力チャンネルが1になることさえ守ればお好みで調整可能。
今回はkernel_size=3を繰り返し適応してみた。
def SpatialAttentionModule(input: tf.keras.Model, kernel_size=3):
avg_pool = tf.keras.layers.Lambda(lambda x: K.mean(x, axis=3, keepdims=True))(input)
max_pool = tf.keras.layers.Lambda(lambda x: K.max(x, axis=3, keepdims=True))(input)
x = tf.keras.layers.Concatenate(axis=3)([avg_pool, max_pool])
for i in [64, 32, 16]:
x = tf.keras.layers.Conv2D(filters=i,
kernel_size=kernel_size,
strides=1,
padding='same',
activation='relu',
kernel_initializer='he_normal',
use_bias=False)(x)
x = tf.keras.layers.Conv2D(filters=1,
kernel_size=kernel_size,
strides=1,
padding='same',
activation='sigmoid',
kernel_initializer='he_normal',
use_bias=False)(x)
return tf.keras.layers.multiply([input, x])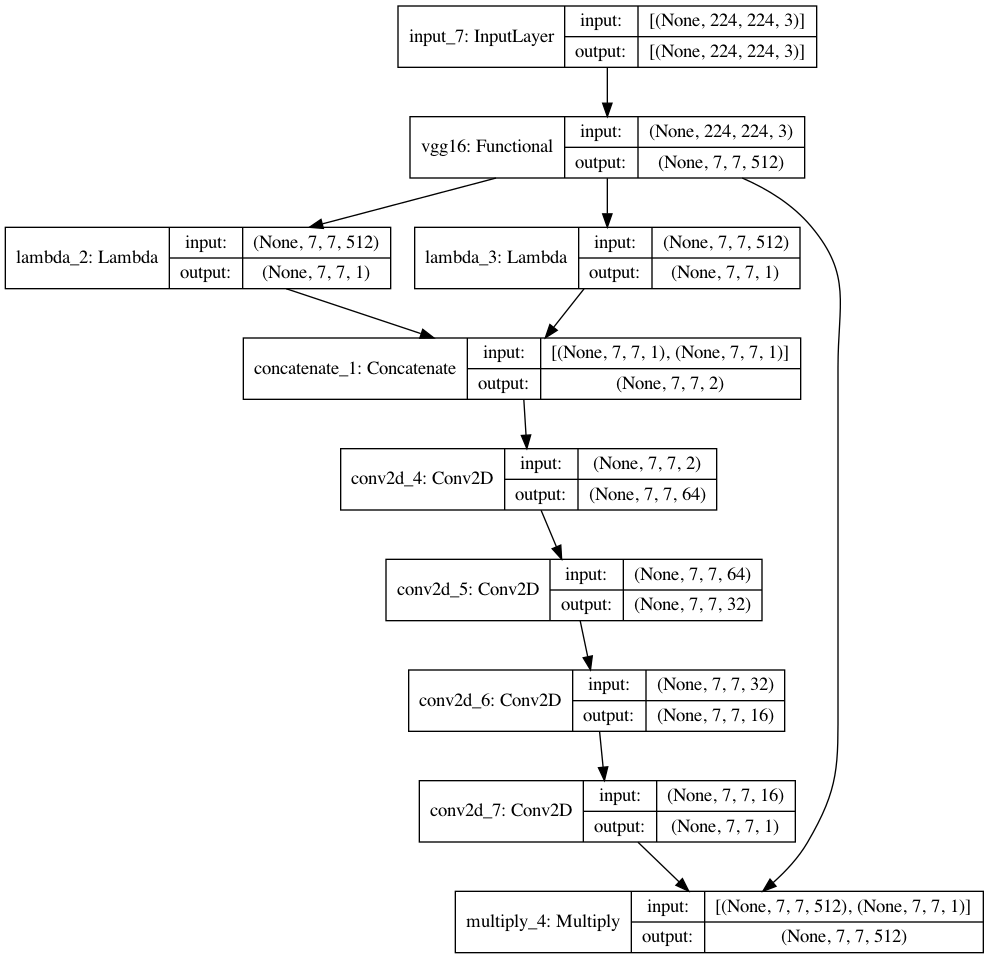
Convolutional Block Attention Module
ChannelAttention→SpatialAttentionの順につなげて完成!
例えばVGG16+CBAMの場合は
inp = tf.keras.layers.Input(shape=(224, 224, 3))
base = tf.keras.applications.VGG16(input_shape=(224, 224, 3), include_top=False, weights=None)
x = base(inp)
x = ChannelAttentionModule(x)
x = SpatialAttentionModule(x)
model = tf.keras.models.Model(inp, x)これでVGG16の重み付き特徴マップが得られた。
最後にFlattenやGlobalAveragePoolingとDenseを付けて、CNNの分類機が完成。
MultiHeadAttentionにしたり、ChannelとSpatialを並列にしたり、順番を入れ替えたり、Attentionの使い方はたくさんありそう。
参考



コメント