
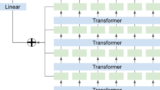
BERTのfine tuningをする際、最終4層のembeddingを使うと精度が向上する可能性がある。

Jigsaw Unintended Bias in Toxicity Classification
Detect toxicity across a diverse range of conversations
kaggle.com

Private 22nd Place solution | Kaggle
Discover what actually works in AI. Join millions of builders, researchers, and labs evaluating agents, models, and fron...
www.kaggle.com
Kaggleで学んだBERTをfine-tuningする際のTips②〜精度改善編〜 | 株式会社AI Shift
AI ShiftのTECH BLOGです。AI技術の情報や活用方法などをご案内いたします。
www.ai-shift.co.jp
サンプルコードはPytorchのばかりだったので、Tensorflow/Kerasでも再現してみた。
軽量モデルで実験したいのでALBERTを使う。
簡単なモデルを組んで眺めてみる。

albert/albert-base-v2 · Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co
from transformers import TFAutoModel, AutoConfig
base_model = "albert-base-v2"
base_model = TFAutoModel.from_pretrained(base_model)
max_len = 2
input_ids = tf.keras.Input(shape=max_len, dtype='int32', name='input_ids')
attention_mask = tf.keras.Input(shape=max_len, dtype='int32', name='attention_mask')
x = base_model(input_ids=input_ids,
attention_mask=attention_mask)
x = x.last_hidden_state
x = tf.keras.layers.GlobalAveragePooling1D()(x)
out = tf.keras.layers.Dense(1)(x)
model = tf.keras.Model(inputs=[input_ids, attention_mask],
outputs=out)
model.compile()
model.summary()
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
input_ids (InputLayer) [(None, 2)] 0 []
attention_mask (InputLayer) [(None, 2)] 0 []
tf_albert_model_2 (TFAlbertMod TFBaseModelOutputWi 11683584 ['input_ids[0][0]',
el) thPooling(last_hidd 'attention_mask[0][0]']
en_state=(None, 2,
768),
pooler_output=(Non
e, 768),
hidden_states=None
, attentions=None)
global_average_pooling1d_1 (Gl (None, 768) 0 ['tf_albert_model_2[0][0]']
obalAveragePooling1D)
dense_1 (Dense) (None, 1) 769 ['global_average_pooling1d_1[0][0
]']
==================================================================================================
Total params: 11,684,353
Trainable params: 11,684,353
Non-trainable params: 0
__________________________________________________________________________________________________Output shapeを見ると、hidden_states=Noneになっており、中間層が取り出せなくなっている。
hidden_statesを出力する方法がないか、huggingfaceで探してみる。

Model outputs · Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co
but we don’t have hidden_states and attentions because we didn’t pass output_hidden_states=True
output_hidden_statesというオプションがあるらしい。
どこで設定するのか探す。

Configuration · Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co
output_hidden_states (bool, optional, defaults to False) — Whether or not the model should return all hidden-states.
configを設定すればいいみたいなので、モデルを再定義する。
base_model = "albert-base-v2"
base_model_config = AutoConfig.from_pretrained(base_model, output_hidden_states=True)
base_model = TFAutoModel.from_pretrained(base_model, config=base_model_config)
max_len = 2
input_ids = tf.keras.Input(shape=max_len, dtype='int32', name='input_ids')
attention_mask = tf.keras.Input(shape=max_len, dtype='int32', name='attention_mask')
x = base_model(input_ids=input_ids,
attention_mask=attention_mask)
x = x.last_hidden_state
x = tf.keras.layers.GlobalAveragePooling1D()(x)
out = tf.keras.layers.Dense(1)(x)
model = tf.keras.Model(inputs=[input_ids, attention_mask],
outputs=out)
model.compile()
model.summary()
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
input_ids (InputLayer) [(None, 2)] 0 []
attention_mask (InputLayer) [(None, 2)] 0 []
tf_albert_model_8 (TFAlbertMod TFBaseModelOutputWi 11683584 ['input_ids[0][0]',
el) thPooling(last_hidd 'attention_mask[0][0]']
en_state=(None, 2,
768),
pooler_output=(Non
e, 768),
hidden_states=((No
ne, 2, 768),
(None, 2, 768),
(None, 2, 768),
(None, 2, 768),
(None, 2, 768),
(None, 2, 768),
(None, 2, 768),
(None, 2, 768),
(None, 2, 768),
(None, 2, 768),
(None, 2, 768),
(None, 2, 768),
(None, 2, 768)),
attentions=None)
global_average_pooling1d_16 (G (None, 768) 0 ['tf_albert_model_8[1][13]']
lobalAveragePooling1D)
dense_7 (Dense) (None, 1) 769 ['global_average_pooling1d_16[0][
0]']
==================================================================================================
Total params: 11,684,353
Trainable params: 11,684,353
Non-trainable params: 0
__________________________________________________________________________________________________
hidden_statesが出力されるようになったので、最終4層を取り出してconcatしていく。
max_len = 2
input_ids = tf.keras.Input(shape=max_len, dtype='int32', name='input_ids')
attention_mask = tf.keras.Input(shape=max_len, dtype='int32', name='attention_mask')
x = base_model(input_ids=input_ids,
attention_mask=attention_mask)
concat = []
for i in range(4):
x1 = x.hidden_states[-1 - i]
x1 = tf.keras.layers.GlobalAveragePooling1D()(x1)
concat.append(x1)
x = tf.keras.layers.Concatenate(axis=1)(concat)
out = tf.keras.layers.Dense(1)(x)
model = tf.keras.Model(inputs=[input_ids, attention_mask],
outputs=out)
model.compile()
model.summary()
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
input_ids (InputLayer) [(None, 2)] 0 []
attention_mask (InputLayer) [(None, 2)] 0 []
tf_albert_model_8 (TFAlbertMod TFBaseModelOutputWi 11683584 ['input_ids[0][0]',
el) thPooling(last_hidd 'attention_mask[0][0]']
en_state=(None, 2,
768),
pooler_output=(Non
e, 768),
hidden_states=((No
ne, 2, 768),
(None, 2, 768),
(None, 2, 768),
(None, 2, 768),
(None, 2, 768),
(None, 2, 768),
(None, 2, 768),
(None, 2, 768),
(None, 2, 768),
(None, 2, 768),
(None, 2, 768),
(None, 2, 768),
(None, 2, 768)),
attentions=None)
global_average_pooling1d_12 (G (None, 768) 0 ['tf_albert_model_8[0][12]']
lobalAveragePooling1D)
global_average_pooling1d_13 (G (None, 768) 0 ['tf_albert_model_8[0][11]']
lobalAveragePooling1D)
global_average_pooling1d_14 (G (None, 768) 0 ['tf_albert_model_8[0][10]']
lobalAveragePooling1D)
global_average_pooling1d_15 (G (None, 768) 0 ['tf_albert_model_8[0][9]']
lobalAveragePooling1D)
concatenate_2 (Concatenate) (None, 3072) 0 ['global_average_pooling1d_12[0][
0]',
'global_average_pooling1d_13[0][
0]',
'global_average_pooling1d_14[0][
0]',
'global_average_pooling1d_15[0][
0]']
dense_6 (Dense) (None, 1) 3073 ['concatenate_2[0][0]']
==================================================================================================
Total params: 11,686,657
Trainable params: 11,686,657
Non-trainable params: 0
__________________________________________________________________________________________________
これで、Tensorflow/KerasでもBERTの最終4層を取り出して結合することが出来た。
コメント